Elastic Stack 实战教�程 5:Elasticsearch Java API Client 开发
本系列 Elastic Stack 实战教程总共涵盖 5 个实验,目的是帮助初学者快速掌握 Elastic Stack 的基本技能。
云起实验室在线体验地址:https://developer.aliyun.com/adc/scenarioSeries/24e7a7a4d56741d0bdcb3ee73c9c22f1
- 实验 1:Elastic Stack 8 快速上手
- 实验 2:ILM 索引生命周期管理
- 实验 3:快照备份与恢复
- 实验 4:使用 Fleet 管理 Elastic Agent 监控应用
- 实验 5:Elasticsearch Java API Client 开发
1 Elasticsearch Jave Client 介绍
Elastic 在 7.16 版本(2021年12月8日)推出了 Elasticsearch Java API Client。在此之前,我们通常使用 High Level REST Client 进行开发,但是 High Level REST Client 存在几个缺陷:
- 1.引入了许多非必要相关的依赖,并且暴露了很多服务器的内部接口。
- 2.一致性差,需要大量的维护工作。
- 3.没有集成 json/object 类型映射,需要自己借助字节缓存区实现。
Elasticsearch Java API Client 有以下三个典型特点:
- 1.对象构造基于建造者模式(Builder Pattern),使用多个简单的对象一步一步构建成一个复杂的对象,增强了客户端代码的可用性和可读性。
- 2.使用 Lambda 构建嵌套对象,使得编写干净、富有表现力的 DSL 变得容易。
- 3.应用程序类能自动映射为 Mapping。
本实验中我们将使用 Elasticsearch Java API Client 进行开发,实现常用的 CRUD 操作。
2 启动实验环境
首先执行以下命令修改系统参数以满足 Elasticsearch 的运行条件。
# 增加进程可使用的最大内存映射区域数
cat >> /etc/sysctl.conf << EOF
vm.max_map_count=262144
EOF
sysctl -p
# 增加进程可使用的最大文件描述符数量
cat >> /etc/security/limits.conf << EOF
elastic - nofile 65535
EOF
ulimit -n 65535
为了方便实验,本节采用 Docker Compose 的方式快速部署 Elasticsearch 集群。执行如下命令,安装 Docker 和 Docker Compose。
apt install -y git
git https://gitee.com/cr7258/elastic-lab.git
curl -sSL https://get.daocloud.io/docker | sh
apt install -y docker-compose
执行如下命令,获取 docker-compose.yml 配置文件,并在后台启动 Elasticsearch 集群。
cd elastic-lab/5_java_develop/
docker-compose up -d
执行 docker-compose ps 命令查看容器运行状态,其中 5java_develop_setup_1 容器是用于创建证书以及设置 elastic 和 kibana_system 用户密码的,执行完毕后会自动退出,我们需要确保其他容器处于 Up 状态。

3 本地环境准备
本地需要提前安装好以下工具:
在本地电脑执行以下命令,克隆代码。
git clone https://gitee.com/cr7258/elastic-lab.git
打开 IntelliJ IDEA 工具,点击 OPEN。
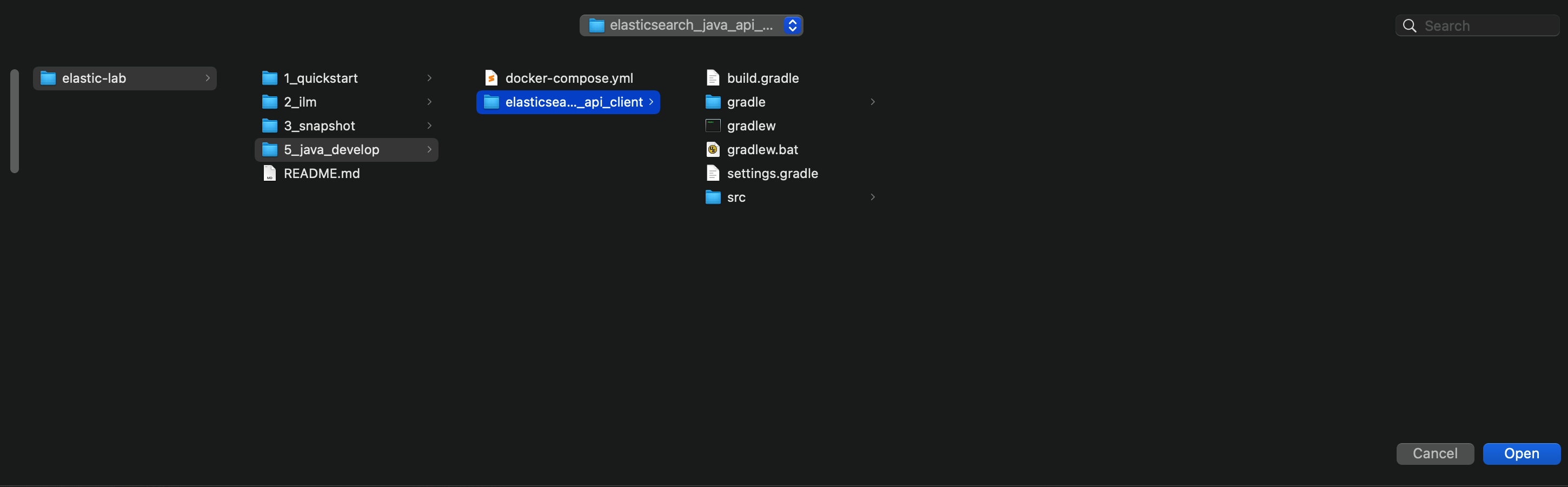
选择打开 elastic-lab -> 5_java_develop -> elasticsearch_java_api_client 项目目录。注意在 IDEA 中打开的是 elasticsearch_java_api_client 目录,这样 IDEA 才可以正确识别出这是一个 gradle 项目,gradle 所需的文件 IDEA 会自动进行下载。
打开 IntelliJ IDEA 设置 -> Build, Execution, Deployment -> Build Tools -> Gradle,将 Run tests using 改为 IntelliJ IDEA。

3 引入依赖
在本实验中,将使用 gradle 项目进行演示,Elasticsearch 所需的依赖如下。
dependencies {
implementation 'co.elastic.clients:elasticsearch-java:8.2.3'
implementation 'com.fasterxml.jackson.core:jackson-databind:2.12.3'
}
另外为了方便我们编写代码,本实验中还使用了 lombok, spring boot 等组件,完整的 gradle 依赖文件请参见 build.gradle。
4 连接集群
创建 Elasticsearch Java API Client 主要分为以下 3 步:
// 1.创建 low-level client
RestClient restClient = RestClient.builder(
new HttpHost("localhost", 9200)).build();
// 2.创建 transport
ElasticsearchTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper());
// 3.创建 api client
ElasticsearchClient client = new ElasticsearchClient(transport);
由于我们部署的 Elasticsearch 8.x 集群设置了用户名和密码,并且启用了 HTTPS 加密,因此我们在构建 low-level client 的使用还需要进行相应的设置。
RestClientBuilder builder = RestClient.builder(httpHost)
.setHttpClientConfigCallback(httpClientBuilder -> httpClientBuilder
.setSSLContext(sslContext) // 设置 SSL 加密通信的方式
.setDefaultCredentialsProvider(credentialsProvider) // 设置用户名密码
.setSSLHostnameVerifier(NoopHostnameVerifier.INSTANCE)); // 不验证 SSL 证书主机名
连接 Elaticsearch 的完整代码可以在 config 目录中获取。
以下两个文件用户需要根据实际情况进行配置,文件路径在 elastic-lab/5_java_develop/elasticsearch_java_api_client/src/main/resources。
- application.yml:设置 Elasticsearch 的连接信息。其中用户名和密码是在 elastic-lab/5_java_develop/.env 文件中设置的,address 是 ECS 服务器对应的 <公网 IP>:9200。
elasticsearch:
schema: https
address: <公网 IP>:9200 # 需要修改
username: elastic
password: elastic123
- ca.crt:由于我们部署的 Elasticsearch 使用的是自签名的 CA,需要设置信任的 CA 证书。在 ECS 上执行以下命令获取证书内容,并保存到 ca.crt 文件中。
docker exec -it 5javadevelop_es01_1 cat config/certs/ca/ca.crt
5 创建实体类
创建一个 Product.java 文件用于保存商品字段。这里使用了 lombok 的 3 个注解会帮助我们生成需要的构造方法以及 Getter, Setter 方法。
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author chengzw
* @description 商品实体类
* @since 2022/8/1
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Product {
String id;
String name;
double price;
}
完成准备工作后,接下来我们将尝试对 Elasticsearch 执行增删改查操作。
6 写入文档
Elasticsearch Java API Client 提供了两种索引文档的方式:
- 1.提供一个应用对象,Elasticsearch Client 负责将对象映射为 JSON。
- 2.直接提供原始的 JSON 数据。
如下所示,我们创建了一个 Product 对象,将数据写入索引 products 中,并使用商品 id 作为 doc id。Elasticsearch Client 会自动将 Product 对象转换为 JSON 数据,然后向 Elasticsearch 发送索引请求。
Product product = new Product("sn10001", "computer", 9999.99);
IndexResponse response = esClient.index(i -> i
.index("products") // 索引名
.id(product.getId()) // doc id
.document(product) // 数据
);
在 IndexingTest.java 文件中可以找到完整代码,点击 indexObject() 方法左边的运行按钮执行上述代码。执行完成后,在最下方可以看到响应结果,可以看到数据已经成功写入 products 索引了。

浏览器输入 http://<ESC 公网 IP>:5601 访问 Kibana 界面。输入用户名 elastic,密码 elastic123,点击 Login in。其中密码是在 elastic-lab/5_java_develop/.env 文件中设置的。

点击 Management -> Dev Tools -> Console,打开 Kibana Console 界面。执行以下命令,查询 products 索引的数据,可以看到 id 为 sn10001 的文档已经被成功写入了。
GET products/_search
# 返回结果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "products",
"_id" : "sn10001",
"_score" : 1.0,
"_source" : {
"id" : "sn10001",
"name" : "computer",
"price" : 9999.99
}
}
]
}
}
当你要索引的数据来自外部时,为这些数据创建实体类可能会很麻烦,这时候你可以使用 withJson() 方法将原始的 JSON 数据作为索引请求的文档内容。
Reader input = new StringReader(
"{'id': 'sn10003', 'name': 'television', 'price': 5500.5}"
.replace('\'', '"'));
IndexRequest<JsonData> request = IndexRequest.of(i -> i
.index("products")
.withJson(input)
);
IndexResponse response = esClient.index(request);
在 IndexingTest.java 文件中可以找到完整代码,点击 indexWithJson() 方法左边的运行按钮执行上述代码。
为了提升写入数据的效率,我们可以提前准备好一批数据,使用 bulk API 在一次网络请求中将数据批量写入 Elasticsearch 中。
List<Product> products = new ArrayList<>();
products.add(new Product("sn10004", "T-shirt", 100.5));
products.add(new Product("sn10005", "phone", 8999.9));
products.add(new Product("sn10006", "ipad", 6555.5));
BulkRequest.Builder br = new BulkRequest.Builder();
for (Product product : products) {
br.operations(op -> op
.index(idx -> idx
.index("products")
.id(product.getId())
.document(product)
) );
}
BulkResponse response = esClient.bulk(br.build());
在 IndexingTest.java 文件中可以找到完整代码,点击 indexBulkObject() 方法左边的运行按钮执行上述代码。

7 查询文档
使用 get 请求可以根据 id 来获取文档。get 请求有两个参数:
- 第一个参数是实际请求,在下面用 fluent DSL 构建。
- 第二个参数是希望将文档的 JSON 映射到的类。
GetResponse<Product> response = esClient.get(g -> g
.index("products")
.id("sn10001"),
Product.class);
在 SearchingTest.java 文件中可以找到完整代码,点击 getById() 方法左边的运行按钮执行上述代码。

接下来我们尝试使用 match 查询语句来搜索 name 字段中包含 computer 关键字的文档,DSL 语句如下所示,我们可以先在 Kibana 上执行以下命令查看结果。
GET products/_search
{
"query": {
"match": {
"name": {
"query": "computer"
}
}
}
}
# 返回结果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.4877305,
"hits" : [
{
"_index" : "products",
"_id" : "sn10001",
"_score" : 1.4877305, # 文档评分
"_source" : { # 文档内容
"id" : "sn10001",
"name" : "computer",
"price" : 9999.99
}
}
]
}
}
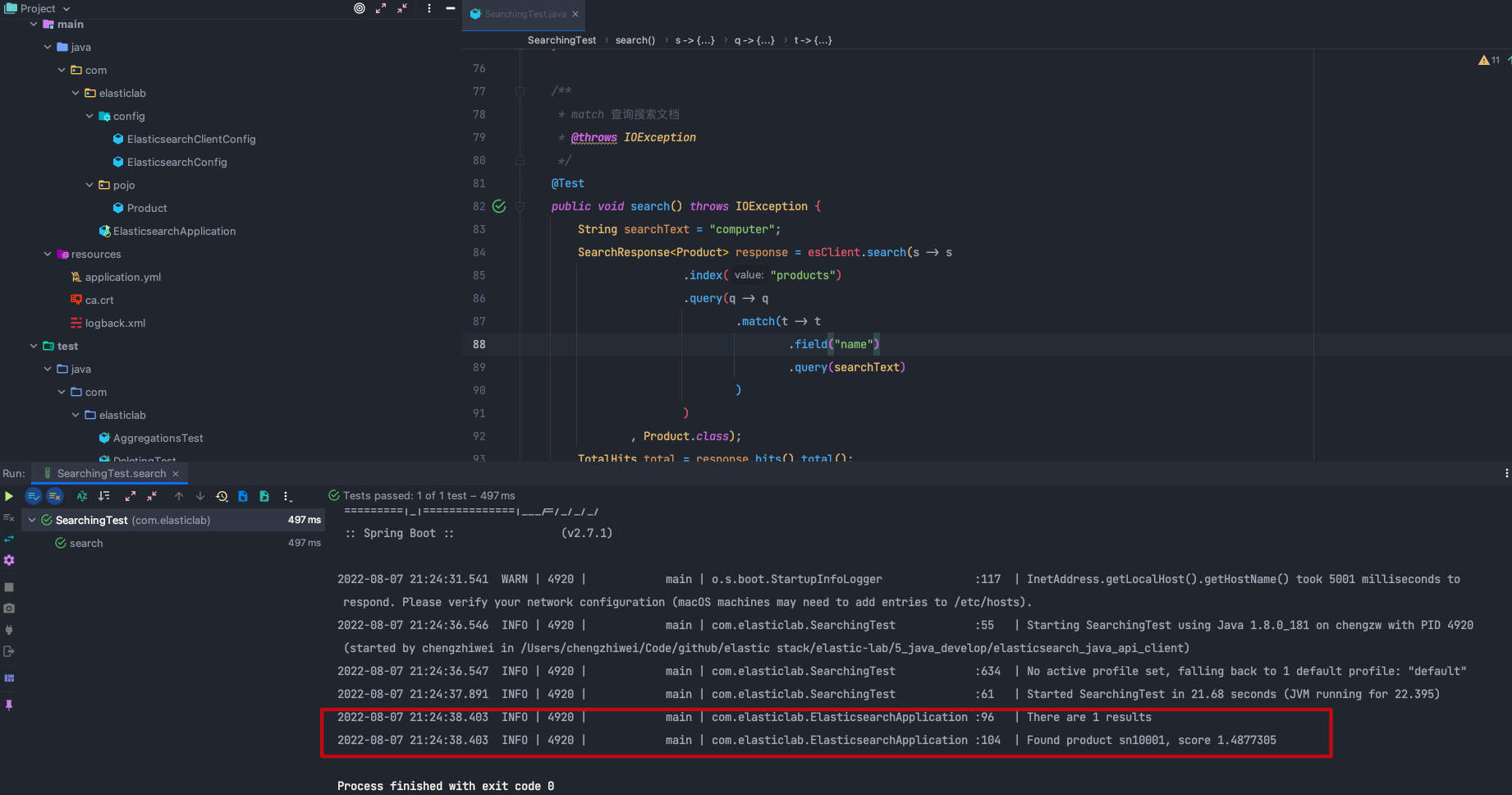
我们可以使用以下代码实现上述的全文查询,可以看出 search 是 Elasticsearch Java API Client 的一大优势,使用 Lambda 构建嵌套对象,大大简化了代码量,并且增强了代码的可读性。
String searchText = "computer";
SearchResponse<Product> response = esClient.search(s -> s
.index("products")
.query(q -> q
.match(t -> t
.field("name")
.query(searchText)
) ) , Product.class);
在 SearchingTest.java 文件中可以找到完整代码,点击 search() 方法左边的运行按钮执行上述代码。
使用聚合查询可以对索引中的数据进行统计,如下所示,我们使用 terms 聚合查询来计算每种商品的数量。由于 name 字段的类型是 text 类型,默认情况下 text 类型是不允许进行聚合操作的,因此这里使用 name 字段的 keyword 类型的子字段 keyword 来进行聚合查询。
GET products/_search
{
"size": 0, // 不返回文档
"aggs": {
"product-term": {
"terms": {
"field": "name.keyword"
}
}
}
}
# 返回结果
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"product-term" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "T-shirt",
"doc_count" : 1
},
{
"key" : "computer",
"doc_count" : 1
},
{
"key" : "ipad",
"doc_count" : 1
},
{
"key" : "phone",
"doc_count" : 1
},
{
"key" : "television",
"doc_count" : 1
}
]
}
}
}
我们可以使用以下代码实现上述的聚合查询,这个例子是一个分析类型的聚合,不需要返回文档内容,因此可以将 size 设置为零,并将搜索结果的目标类设置为 Void.class。
SearchResponse<Void> response = esClient.search(b -> b
.index("products")
.size(0)
.aggregations("product-term", a -> a
.terms(t -> t
.field("name.keyword"))
), Void.class);
在 AggregationsTest.java 文件中可以找到完整代码,点击 productTerm() 方法左边的运行按钮执行上述代码。

8 删除文档
删除文档通常有两种方式:
- 1.指定 doc id 删除单条文档。
- 2.通过 deleteByQuery 查询匹配删除单条或多条文档。
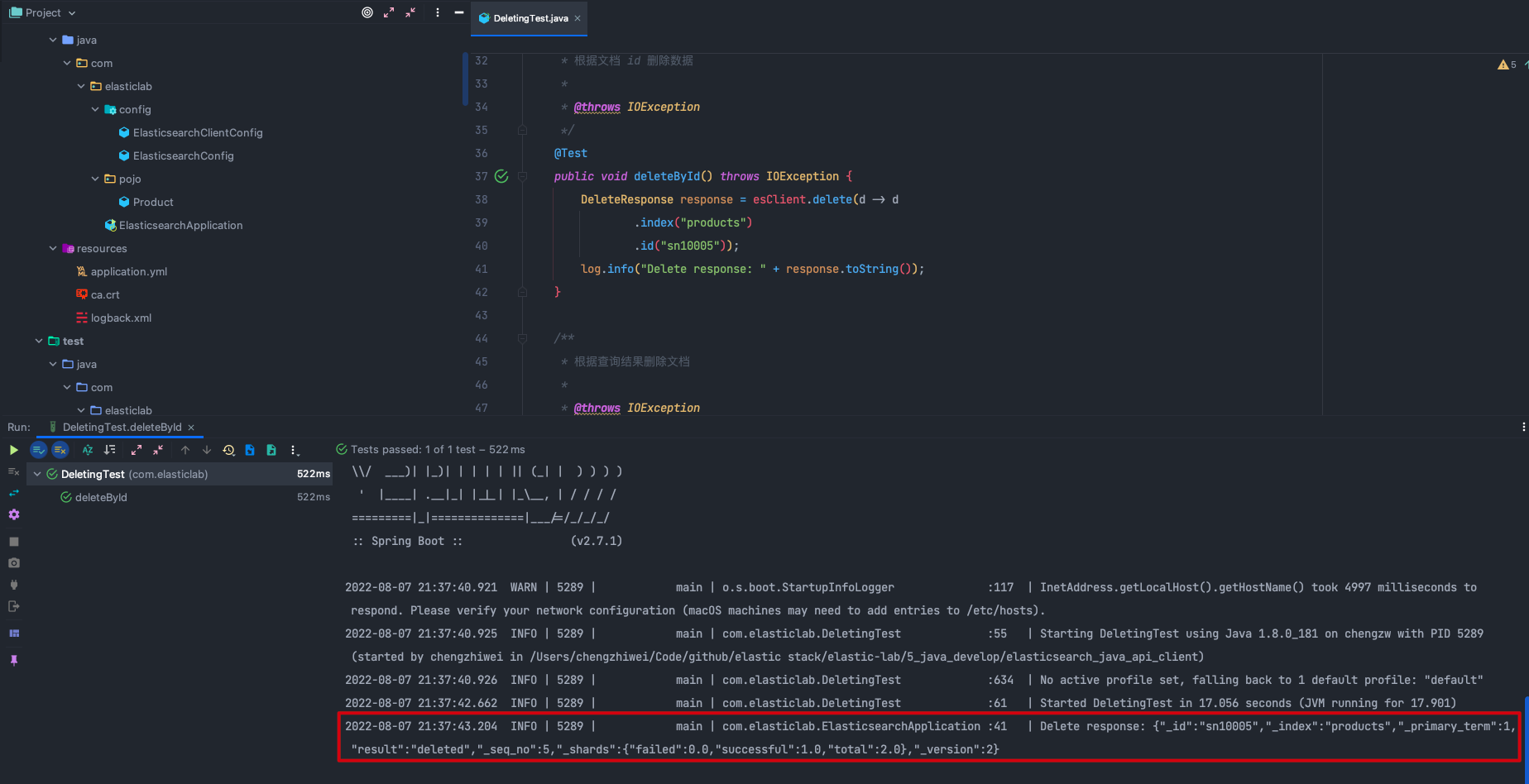
如下所示,指定删除索引 products 中 id 为 sn10005 的文档。
DeleteResponse response = esClient.delete(d -> d
.index("products")
.id("sn10005"));
在 DeletingTest.java 文件中可以找到完整代码,点击 deleteById() 方法左边的运行按钮执行上述代码。
批量删除文档可以使用 deleteByQuery。如下所示,删除索引 products 中所有 name 字段的值是 ipad 的文档。
String searchText = "ipad";
DeleteByQueryResponse response = esClient.deleteByQuery(d ->
d.index("products")
.query(q -> q
.match(t -> t
.field("name")
.query(searchText))));
在 DeletingTest.java 文件中可以找到完整代码,点击 deleteByQuery() 方法左边的运行按钮执行上述代码。

9 更新文档
和删除文档类似,更新文档通常也有两种方式:
- 1.指定 doc id 更新单条文档。
- 2.通过 updateByQuery 查询匹配更新单条或多条文档。
我们在更新文档的时候可以在请求体的 doc 参数中指定要更新的字段内容。如下所示,更新 doc id 为 sn10001 的文档的 price 字段值为 7777.77。
POST products/_update/sn10001
{
"doc": {
"price": 7777.77
}
}
我们可以使用以下代码实现上述的单条更新操作,首先创建一个 Product 对象,然后设置对象的 price 字段值为 7777.77,然后使用 update 请求设置更新的索引名和 doc id,并传入 Product 对象。
Product product = new Product();
product.setPrice(7777.77);
UpdateResponse<Product> response = esClient.update(u -> u
.index("products")
.id("sn10005")
.doc(product), Product.class);
在 UpdatingTest.java 文件中可以找到完整代码,点击 updateById() 方法左边的运行按钮执行上述代码。

在 Kibana 查询 doc id 为 sn10001 的文档,可以看到 price 字段值已经被成功修改为 7777.77 了。
GET products/_doc/sn10001
# 返回结果
{
"_index" : "products",
"_id" : "sn10001",
"_version" : 2,
"_seq_no" : 7,
"_primary_term" : 1,
"found" : true,
"_source" : {
"id" : "sn10001",
"name" : "computer",
"price" : 7777.77
}
}
批量更新文档可以使用 updateByQuery。如下所示,将索引 products 中所有 name 字段的值是 T-shirt 的文档的 price 字段值增加 1000,使用 painless script 可以实现更加复杂的操作。
POST products/_update_by_query
{
"query": {
"match": {
"name": "T-shirt"
}
},
"script": {
"source": """
ctx._source.price += 1000
""",
"lang": "painless"
}
}
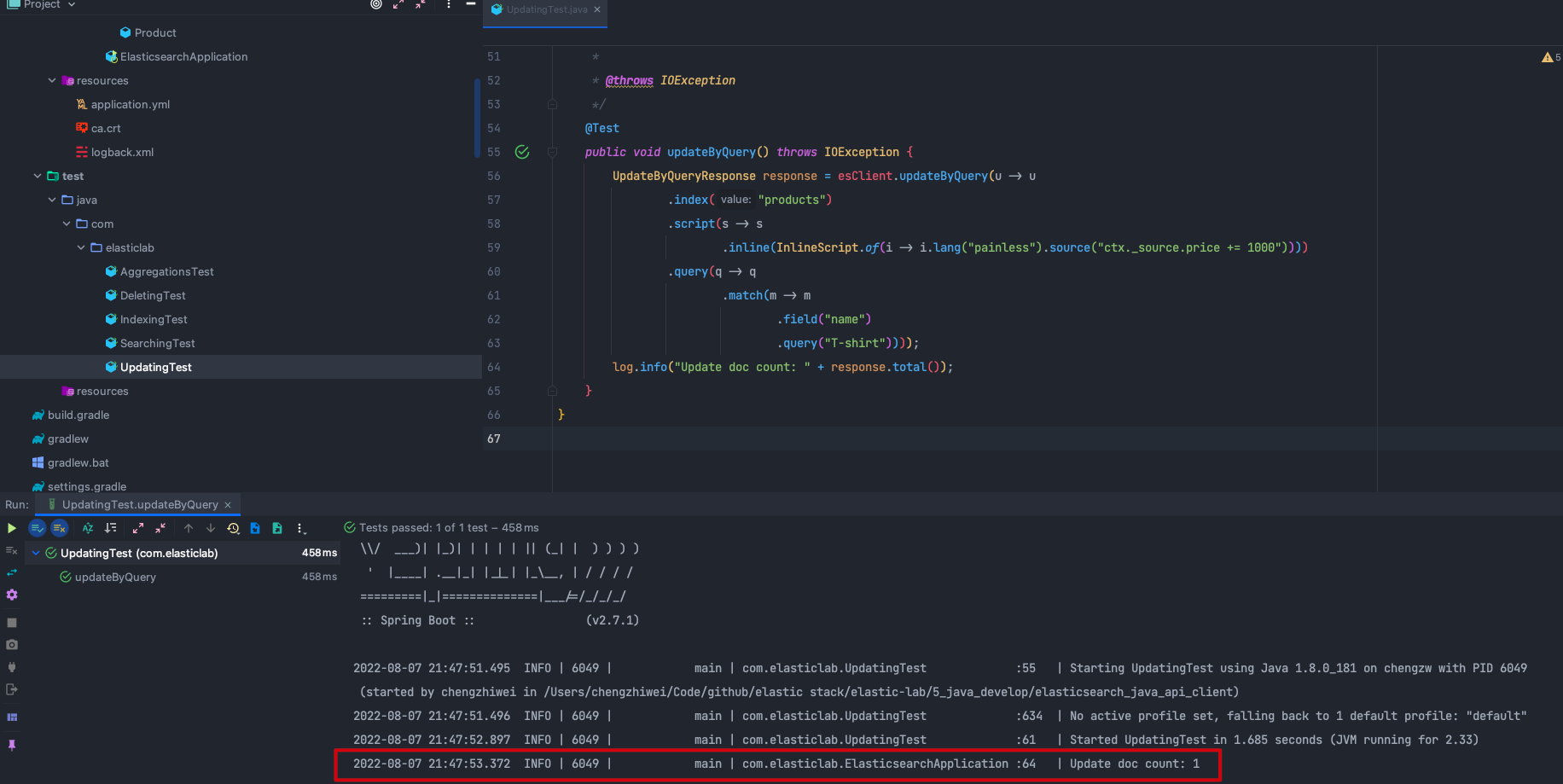
我们可以使用以下代码实现上述的批量更新操作,在 InlineScript 中可以设置批量更新使用的 painless script。
UpdateByQueryResponse response = esClient.updateByQuery(u -> u
.index("products")
.script(s -> s
.inline(InlineScript.of(i -> i.lang("painless").source("ctx._source.price += 1000"))))
.query(q -> q
.match(m -> m
.field("name")
.query("T-shirt"))));
在 UpdatingTest.java 文件中可以找到完整代码,点击 updateByQuery() 方法左边的运行按钮执行上述代码。
查询 name 字段值是 T-shirt 的文档,可以看到 price 字段值已经增加 1000 了。
GET products/_search
{
"query": {
"match": {
"name": "T-shirt"
}
}
}
# 返回结果
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.2199391,
"hits" : [
{
"_index" : "products",
"_id" : "sn10004",
"_score" : 1.2199391,
"_source" : {
"price" : 1100.5,
"name" : "T-shirt",
"id" : "sn10004"
}
}
]
}
}