Elastic Stack 实战教程 1:Elastic Stack 8 快速上手
本系列 Elastic Stack 实战教程总共涵盖 5 个实验,目的是帮助初学者快速掌握 Elastic Stack 的基本技能。
云起实验室在线体验地址:https://developer.aliyun.com/adc/scenarioSeries/24e7a7a4d56741d0bdcb3ee73c9c22f1
- 实验 1:Elastic Stack 8 快速上手
- 实验 2:ILM 索引生命周期管理
- 实验 3:快照备份与恢复
- 实验 4:使用 Fleet 管理 Elastic Agent 监控应用
- 实验 5:Elasticsearch Java API Client 开发
1 Elastic Stack 介绍
Elastic Stack 的核心产品包括 Elasticsearch、Kibana、Beats 和 Logstash,可以帮助用户安全可靠地获取任何来源、任何格式的数据,并实时地对数据进行搜索、分析和可视化。

Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,Elasticsearch 作为 Elastic Stack 的核心,集中存储数据。
Kibana 提供了酷炫的可视化界面, 使用 Kibana 可以对 Elasticsearch 索引中的数据进行搜索、查看以及交互操作,用户可以利用图表、表格以及地图对数据进行多元化的分析和呈现。
Beats 和 Logstash 提供了数据摄取的功能。其中 Beats 是一个轻量级的数据摄取工具,Logstash 则提供了类似于 ELT 的功能。

在下面的实验中,将会介绍如何在 ECS 实例上部署 Elasticsearch 和 Kibana,以及 Elasticsearch 常用 API 的使用方法。
2 部署 Elasticsearch
本小节将指导您如何部署一个单节点的 Elasticsearch 集群。
出于安全原因,Elasticsearch 默认不允许使用 root 用户启动。执行以下命令,创建 elastic 用户,设置密码为 elastic123 ,并切换到该用户。
useradd -s /bin/bash -m elastic
echo "elastic:elastic123" | chpasswd
su - elastic
下载和解压 Elasticsearch 安装文件。
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.2.3-linux-x86_64.tar.gz
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.2.3-linux-x86_64.tar.gz.sha512
shasum -a 512 -c elasticsearch-8.2.3-linux-x86_64.tar.gz.sha512
tar -xzf elasticsearch-8.2.3-linux-x86_64.tar.gz
cd elasticsearch-8.2.3/
Elasticsearch 目录结构如下所示。

执行如下命令,启动 Elasticsearch。
./bin/elasticsearch
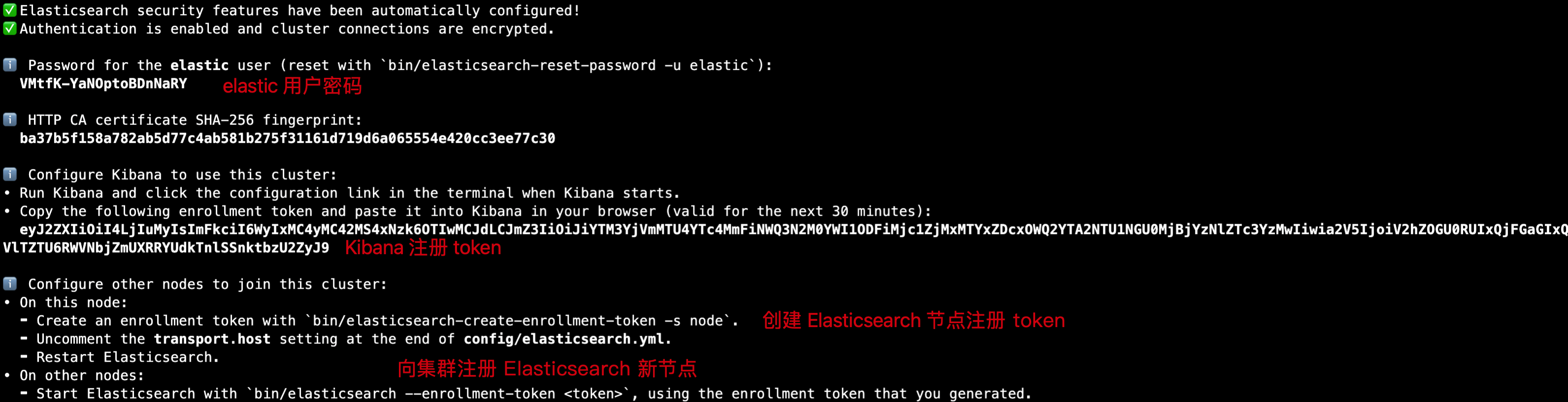
启动成功后,会输出以下内容,保存好以下两个内容:
- elastic 用户密码。
- Kibana 注册 token。
在启动过程中 Elasticsearch 需要连接公网获取 IP 地址地理位置的相关信息,由于网络原因可能导致数据下载失败而产生以下报错,该报错对 Elasticsearch 运行没有影响,用户可以忽略。

浏览器输入 https://<ESC 公网 IP>:9200 访问 Elasticsearch,注意本场景中提供了两台 ECS 实例,请填写正确的 ECS 公网 IP 地址。输入用户名:elastic,密码:VMtfK-YaNOptoBDnNaRY(根据上面输出填写)。用户认证通过后,会显示以下内容:
- name: 节点名,默认使用主机名作为节点名。
- cluster_name: 集群名,默认的集群名是 elasticsearch,同一个集群中的所有节点的 cluster.name 要保持一致。
- cluster_uuid: 集群的唯一标识符。
- version: 版本信息。
 至此我们已经成功部署了一个单节点的 Elasticsearch 集群。
至此我们已经成功部署了一个单节点的 Elasticsearch 集群。
3 部署 Kibana
本小节将指导您如何部署 Kibana 并连接到 Elasticsearch。
打开一个新的终端, 切换到 elastic 用户。
su - elastic
执行如下命令,下载和解压 Kibana 安装文件。
curl -O https://artifacts.elastic.co/downloads/kibana/kibana-8.2.3-linux-x86_64.tar.gz
curl https://artifacts.elastic.co/downloads/kibana/kibana-8.2.3-linux-x86_64.tar.gz.sha512 | shasum -a 512 -c -
tar -xzf kibana-8.2.3-linux-x86_64.tar.gz
cd kibana-8.2.3/
Kibana 目录结构如下所示:

编辑 config/kibana.yml 配置文件,修改以下内容,允许 Kibana 服务监听本机所有 IP 地址。
server.host: "0.0.0.0"
执行如下命令,启动 Kibana。
./bin/kibana
启动成功后,会输出以下内容。

浏览器输入 http://<ESC 公网 IP>:5601/?code=321491 访问 Kibana 界面,code=321491 修改为上图终端输出的内容。在 Enrollment token 输入框中填入第 1 小节启动 Elasticsearch 后输出的 Kibana 注册 token,然后点击 Configure Elastic。

接着 Kibana 会自动完成注册设置。

Kibana 注册成功后会出现登录界面,输入 elastic 用户名密码登录 Elasticsearch。

在注册成功后,在 config/kibana.yml 配置文件中会自动添加 Elasticsearch 相关的连接信息和 SSL 证书,用户无需关注。

4 往集群中注册新节点
本小节将指导您如何往 Elasticsearch 集群中注册新节点。
首先在第一个终端,键盘按 Ctrl + C 停止在前台运行的 Elasticsearch 进程。
4.1 修改第一个节点配置
默认情况下,Elasticsearch transport 服务的 9300 端口只在 127.0.0.1 上监听。如果要想和其他节点进行交互,我们需要更改当前节点的 config/elasticsearch.yml 文件,修改内容如下。
transport.host: 0.0.0.0
当允许 transport 服务在非环回地址监听后,Elasticsearch 将处于生产模式,在启动之前需要进行一些引导检查,我们需要修改一些系统参数确保能够通过检查。
在当前 elastic 用户下执行 exit 命令退回 root 用户,在 root 用户修改以下系统参数。
增加进程可使用的最大内存映射区域数,编辑 /etc/sysctl.conf 文件,添加以下内容。
vm.max_map_count=262144
执行以下命令立即生效:
sysctl -p
增加进程可使用的最大文件描述符数量,编辑 /etc/security/limits.conf 文件,添加以下内容。
elastic - nofile 65535
执行以下命令立即生效:
ulimit -n 65535
切换到 elastic 用户。
su - elastic
重新启动 Elasticsearch,-d 参数表示在后台运行 Elasticsearch。
cd elasticsearch-8.2.3
./bin/elasticsearch -d
执行 tail -f logs/elasticsearch.log 命令可以查看 Elasticsearch 的启动日志。
确认 Elasticsearch 启动成功以后,执行以下命令,生成新的注册 token,用于注册新节点到 Elasticsearch 集群。
bin/elasticsearch-create-enrollment-token -s node
# 返回的 token
eyJ2ZXIiOiI4LjIuMyIsImFkciI6WyIxMC4yMC42MS4xNzk6OTIwMCJdLCJmZ3IiOiJiYTM3YjVmMTU4YTc4MmFiNWQ3N2M0YWI1ODFiMjc1ZjMxMTYxZDcxOWQ2YTA2NTU1NGU0MjBjYzNlZTc3YzMwIiwia2V5IjoiY1A3WGxJRUJFLU9sOTh0Qm5Deno6UXZTWEdOZ3BTYktaWXdic19pTS1fUSJ9
4.2 注册新节点
接下来配置新节点,打开一个新的终端, 执行 ssh root@<ESC 公网 IP> 命令登录到另一个节点上。
在 root 用户下修改以下系统参数。 增加进程可使用的最大内存映射区域数,编辑 /etc/sysctl.conf 文件,添加以下内容。
vm.max_map_count=262144
执行以下命令立即生效:
sysctl -p
增加进程可使用的最大文件描述符数量,编辑 /etc/security/limits.conf 文件,添加以下内容。
elastic - nofile 65535
执行以下命令立即生效:
ulimit -n 65535
执行以下命令,创建 elastic 用户,设置密码为 elastic123 ,并切换到该用户。
useradd -s /bin/bash -m elastic
echo "elastic:elastic123" | chpasswd
su - elastic
下载和解压 Elasticsearch 安装文件。
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.2.3-linux-x86_64.tar.gz
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.2.3-linux-x86_64.tar.gz.sha512
shasum -a 512 -c elasticsearch-8.2.3-linux-x86_64.tar.gz.sha512
tar -xzf elasticsearch-8.2.3-linux-x86_64.tar.gz
cd elasticsearch-8.2.3/
在当前节点的 config/elasticsearch.yml 文件中,添加以下内容。
transport.host: 0.0.0.0
执行以下命令,启动新节点,并往 Elasticsearch 集群进行注册,在 --enrollment-token 参数后面跟上前面生成的 token。
bin/elasticsearch --enrollment-token eyJ2ZXIiOiI4LjIuMyIsImFkciI6WyIxMC4yMC42MS4xNzk6OTIwMCJdLCJmZ3IiOiJiYTM3YjVmMTU4YTc4MmFiNWQ3N2M0YWI1ODFiMjc1ZjMxMTYxZDcxOWQ2YTA2NTU1NGU0MjBjYzNlZTc3YzMwIiwia2V5IjoiY1A3WGxJRUJFLU9sOTh0Qm5Deno6UXZTWEdOZ3BTYktaWXdic19pTS1fUSJ9
在 Kibana 的 Dev Tools 中执行以下命令,查询集群中的节点,可以看到第二个节点已经成功加入集群。默认使用主机名作为节点名。
GET _cat/nodes?v
# 返回结果
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
10.20.61.179 21 95 10 0.14 0.27 0.20 cdfhilmrstw * elastic-demo
10.20.61.180 6 85 2 0.74 0.28 0.09 cdfhilmrstw - node-2
在注册成功后,在 config/elasticsearch.yml 配置文件中会自动添加 Elasticsearch 相关的配置信息,用户无需关注。

节点的所需 SSL 证书也会自动拷贝到新节点上。

5 写入文档
本小节将指导您如何将数据写入 Elasticsearch。
Elasticsearch 具有 Schemaless的能力,能够自动检测 JSON 源数据的类型并为数据中的新字段创建新的映射。正是由于这种灵活的特性,使得我们可以不用事先为索引定义 mapping(映射)就可以往索引中写入数据。
点击 Management -> Dev Tools -> Console,打开 Kibana Console 界面。在左侧面板中执行以下命令,往 books 索引中写入一条文档。Elasticsearch 会自动帮我们创建 books 索引。
# 写入单条文档
POST books/_doc
{
"title": "Programming Kubernetes",
"isbn": "9781617297618",
"pageCount": 345,
"category": "Cloud Native"
}
在右侧��面板会返回响应结果,可以看到文档已经被成功创建了,doc id 是随机生成的 YTeEhYEBGHa5rBjoiL-Q。

如果想要在写入文档时指定 doc id,可以使用 PUT <index-name>/_doc/<doc-id>。如果指定 id 的文档不存在,则直接创建新的文档;否则先删除现有文档,再创建新的文档,同时文档版本号(_version, _seq_no)会增加。
# 设置写入的 doc id 为 1
PUT books/_doc/1
{
"title": "Istio in Action",
"isbn": "9781617295829",
"pageCount": 480,
"category": "Cloud Native"
}
使用 bulk API 可以在单次请求中批量写入多条文档,这样能极大减少写入请求的网络开销。
POST books/_bulk
{"index": {"_id": 2}}
{"title":"Elasticsearch in Action","isbn":"9781617299858","pageCount":475,"category": "Search"}
{"index": {"_id": 3}}
{"title":"Relevant Search","isbn":"9781617292774","pageCount":360,"category": "Search"}
{"index": {"_id": 4}}
{"title":"Modern Java in Action","isbn":"9781617293566","pageCount":592,"category": "Java"}
6 查询文档
本小节将指导您如何查询 Elasticsearch 中的数据。
使用 GET <index-name>/_doc/<doc-id> 可以获取索引中指定 doc id 的文档。执行以下命令,获取 doc id 为 1 的文档。
GET books/_doc/1
响应结果如下,除了返回文档的内容以外,还包含了一些元数据字段:
- _index: 文档所属的索引名。
- _id: 文档 id。
- _version: 文档的版本号,_version 属于单个文档,修改删除操作会在当前文档的 _version 基础上自增 1。
- _seq_no: 索引的版本号,_seq_no 属于整个索引,修改删除操作会整个索引的 _seq_no 基础上自增 1。
- _primary_term: 每当主分片发生重新分配时(例如故障转移,主分片选举),_primary_term 会自增 1。该参数主要是为了防止主分片重新分配到新节点后,原主分片所在的节点恢复后覆盖新节点上主分片写入的数据。
- _source: 文档原始的 JSON 数据。
{
"_index" : "books", // 索引名
"_id" : "1",
"_version" : 2,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : { // 文档内容
"title" : "Istio in Action",
"isbn" : "9781617295829",
"pageCount" : 480,
"category" : "Cloud Native"
}
}
查询 books 索引,不指定任何过滤条件,默认最多返回 10 条文档。
GET books/_search
返回了当前索引中的全部 4 条文档。
- took: 搜索请求总共耗费了多少毫秒。
- timed_out: 查询是否超时。如果超时,Elasticsearch 将会返回超时前已经成功从每个分片获取的结果。
- _shards: 查询的分片计数。
- total: 需要查询的分片总数,包括未分配的分片。
- successful: 执行请求成功的分片数。
- skipped: 跳过的分片数,Elasticsearch 在查询前先会通过轻量级的检查判断分片上是否含符合条件的文档,通常发生在查询中带有 range 过滤条件的情况下。
- failed: 执行请求失败的分片数。
- hits: 返回的文档和元数据。
- total: 匹配到的文档总数。
- max_score: 返回最高的文档分数。
- hits: 文档对象数组。
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "books",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"title" : "Istio in Action",
"isbn" : "9781617295829",
"pageCount" : 480,
"category" : "Cloud Native"
}
},
{
"_index" : "books",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"title" : "Elasticsearch in Action",
"isbn" : "9781617299858",
"pageCount" : 475,
"category" : "Search"
}
},
{
"_index" : "books",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"title" : "Relevant Search",
"isbn" : "9781617292774",
"pageCount" : 360,
"category" : "Search"
}
},
{
"_index" : "books",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"title" : "Modern Java in Action",
"isbn" : "9781617293566",
"pageCount" : 592,
"category" : "Java"
}
},
{
"_index" : "books",
"_id" : "ZDfNjoEBGHa5rBjoYL_5",
"_score" : 1.0,
"_source" : {
"title" : "Programming Kubernetes",
"isbn" : "9781617297618",
"pageCount" : 345,
"category" : "Cloud Native"
}
}
]
}
}
Elasticsearch 在不设置字段映射的情况下, 默认会将字符串类型的字段设置成 text 类型,并加上一个 keyword 子字段,子字段的类型是 keyword。text 类型的字段默认使用 standard 分析器解析文本,按照 Unicode 文本分割算法对文本进行切分,去除标点符号,并将切分后的单词转换为小写,主要用于全文搜索;keyword 类型的字段使用 keyword 分析器解析文本,不对文本进行切分,保留原始的文本内容,用于精确匹配和聚合查询。
使用 match 查询 title 字段中含有 action 的文档,不区分大小写。
GET books/_search
{
"query": {
"match": {
"title": "action"
}
}
}
这次只返回了 title 中含有 action 的 3 条文档。
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 0.35667494,
"hits" : [
{
"_index" : "books",
"_id" : "1",
"_score" : 0.35667494,
"_source" : {
"title" : "Istio in Action",
"isbn" : "9781617295829",
"pageCount" : 480,
"category" : "Cloud Native"
}
},
{
"_index" : "books",
"_id" : "2",
"_score" : 0.35667494,
"_source" : {
"title" : "Elasticsearch in Action",
"isbn" : "9781617299858",
"pageCount" : 475,
"category" : "Search"
}
},
{
"_index" : "books",
"_id" : "4",
"_score" : 0.31387398,
"_source" : {
"title" : "Modern Java in Action",
"isbn" : "9781617293566",
"pageCount" : 592,
"category" : "Java"
}
}
]
}
}
使用 term 查询精确匹配 category.keyword 字段值是 Cloud Native 的文档。上面介绍到 keyword 类型的字段保留原始文本,用于精确匹配,因此这里的查询区分大小写,如果查询 cloud native 将匹配不到文档。
GET books/_search
{
"query": {
"term": {
"category.keyword": {
"value": "Cloud Native"
}
}
}
}
返回结果如下,匹配到了 2 条文档。
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.87546873,
"hits" : [
{
"_index" : "books",
"_id" : "1",
"_score" : 0.87546873,
"_source" : {
"title" : "Istio in Action",
"isbn" : "9781617295829",
"pageCount" : 480,
"category" : "Cloud Native"
}
},
{
"_index" : "books",
"_id" : "ZDfNjoEBGHa5rBjoYL_5",
"_score" : 0.87546873,
"_source" : {
"title" : "Programming Kubernetes",
"isbn" : "9781617297618",
"pageCount" : 345,
"category" : "Cloud Native"
}
}
]
}
}
如果我们想同时通过多个条件查询文档,可以使用 bool 组��合查询。bool 查询接受以下 4 个参数:
- must: must 中的所有条件都要符合,计算相关性得分。
- must_not: 排除所有符合 must_not 条件的文档,不计算相关性得分。
- filter: 只过滤符合条件的文档,不计算相关性得分。
- should:
- 情况 1: bool 查询中只包含 should ,不包含 must 查询,此时文档必须满足至少一个条件,minimum_should_match 可以控制满足条件的个数或者百分比。
- 情况 2:bool 查询中同时包含 should 和 must 查询,此时文档不必满足 should 中的条件,但是如果满足条件,会增加相关性得分。
下面的查询表示同时满足 title 字段中含有 action 以及 category.keyword 字段值是 Cloud Native 两个条件的文档才算匹配。
GET books/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "action"
}
},
{
"term": {
"category.keyword": {
"value": "Cloud Native"
}
}
}
]
}
}
}
返回结果如下,只有 1 条文档同时满足以上两个条件。
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.3991625,
"hits" : [
{
"_index" : "books",
"_id" : "1",
"_score" : 1.3991625,
"_source" : {
"title" : "Istio in Action",
"isbn" : "9781617295829",
"pageCount" : 480,
"category" : "Cloud Native"
}
}
]
}
}
Elasticsearch 除了文本搜索以外,还支持聚合查询,可以帮助我们对数据进行分析。例如我们可以通过以下命令查询 books 索引中每种类别书籍的数量。
GET books/_search
{
"size": 0, // 不返回文档,只返回聚合结果
"aggs": { // 聚合查询
"my_category_agg": {
"terms": {
"field": "category.keyword",
"size": 10
}
}
}
}
返回结果如下,可以看到 Cloud Native 类别的书籍有 2 个,Search 类别的书籍有 1 个, Java 类别的书籍有 1 个。
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"my_category_agg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "Cloud Native",
"doc_count" : 2
},
{
"key" : "Search",
"doc_count" : 2
},
{
"key" : "Java",
"doc_count" : 1
}
]
}
}
}
7 更新文档
本小节将指导您如何更新 Elasticsearch 中的数据。
使用 PUT <index-name>/_doc/<doc-id> 这种语法的效果是覆盖数据,可以理解为先删除现有文档,再创建新的文档。��如果该 doc id 的文档不存在,则创建一个新的文档。
PUT books/_doc/1
{
"title": "Cloud Native Patterns",
"isbn": "9781617294297",
"category": "Cloud Native"
}
查询 doc id 为 1 的这条文档。
GET books/_doc/1
返回结果如下,新的文档中只含有我们更新时指定 3 个字段,而原始文档中的 pageCount 字段消失了。
{
"_index" : "books",
"_id" : "1",
"_version" : 2,
"_seq_no" : 5,
"_primary_term" : 1,
"found" : true,
"_source" : {
"title" : "Cloud Native Patterns",
"isbn" : "9781617294297",
"category" : "Cloud Native"
}
}
那么如何在不影响文档中其他字段的情况下对文档进行更新呢?可以使用 PUT <index-name>/_update/<doc-id> 语法,在请求体的 doc 参数中指定要更新的字段内容。
POST books/_update/1
{
"doc": { // 指定要更新的字段内容
"pageCount": 400
}
}
查询 doc id 为 1 的这条文档。
GET books/_doc/1
返回结果如下,pageCount 字段的值被设置为了 400,其他字段保持不变。
{
"_index" : "books",
"_id" : "1",
"_version" : 3,
"_seq_no" : 6,
"_primary_term" : 1,
"found" : true,
"_source" : {
"title" : "Cloud Native Patterns",
"isbn" : "9781617294297",
"category" : "Cloud Native",
"pageCount" : 400
}
}
Elasticsearch 还支持通过脚本的方式更新字段,通过编写脚本可以实现更加复杂的处理逻辑。下面命令表示,当 pageCount 字段的值大于 200 时,将 pageCount 的值加 200,否则将 pageCount 的值设置为 99。
POST books/_update/1
{
"script": {
"source": """
if(ctx._source.pageCount > 200) {
ctx._source.pageCount += 200;
}else {
ctx._source.pageCount = 99;
}
"""
}
}
返回结果如下,由于 pageCount 原本的值 400 大于 200,因此 pageCount 的值被更新为了 600(400+200)。
{
"_index" : "books",
"_id" : "1",
"_version" : 4,
"_seq_no" : 7,
"_primary_term" : 1,
"found" : true,
"_source" : {
"title" : "Cloud Native Patterns",
"isbn" : "9781617294297",
"category" : "Cloud Native",
"pageCount" : 600
}
}
除了单条更新文档以外,我们还可以使用 Update By Query API 来根据查询条件批量更新文档。执行以下命令,为 pageCount 小于 400 的书籍添加一个新的字段 description,设置值为 quickStart。
POST books/_update_by_query
{
"query": {
"range": {
"pageCount": {
"lte": 400
}
}
},
"script": {
"source": "ctx._source.description = 'quickStart'"
}
}
不论是关系型数据库,还是 Elasticsearch,只要有数据更新,并发控制是�永恒的话题。在 Elasticsearch 中,数据的更新基于版本进行乐观锁并发控制。在 Elasticsearch 6.7 版本之后推荐使用 _seq_no 和 _primary_term 两个参数进行并发控制。
先获取当前索引的 _seq_no 和 _primary_term 的值。
GET books/_doc/1
返回结果如下。
{
"_index" : "books",
"_id" : "1",
"_version" : 4,
"_seq_no" : 9,
"_primary_term" : 1,
"found" : true,
"_source" : {
"pageCount" : 400,
"isbn" : "9781617294297",
"description" : "quickStart",
"title" : "Cloud Native Patterns",
"category" : "Cloud Native"
}
}
更新文��档时指定 _seq_no 和 _primary_term。
PUT books/_doc/1?if_seq_no=9&if_primary_term=1
{
"doc": {
"pageCount": 500
}
}
返回结果如下,提示更新成功。
{
"_index" : "books",
"_id" : "1",
"_version" : 5,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 10,
"_primary_term" : 1
}
如果指定的 _seq_no 和 _primary_term 不等于当前更新的文档中的值,那么更新将会失败。
PUT books/_doc/1?if_seq_no=9&if_primary_term=1
{
"doc": {
"pageCount": 500
}
}
返回结果如下,提示版本冲突,当前文档 _seq_no 的值已经更新为 10 了,但是还使用老版本 _seq_no 的值 9 来更新。
{
"error" : {
"root_cause" : [
{
"type" : "version_conflict_engine_exception",
"reason" : "[1]: version conflict, required seqNo [9], primary term [1]. current document has seqNo [10] and primary term [1]",
"index_uuid" : "3bYmNTQpRyqOmcwUG1HvNg",
"shard" : "0",
"index" : "books"
}
],
"type" : "version_conflict_engine_exception",
"reason" : "[1]: version conflict, required seqNo [9], primary term [1]. current document has seqNo [10] and primary term [1]",
"index_uuid" : "3bYmNTQpRyqOmcwUG1HvNg",
"shard" : "0",
"index" : "books"
},
"status" : 409
}
8 删除文档
本小节将指导您如何删除 Elasticsearch 中的数据。
使用 DELETE <index-name>/_doc/<doc-id> 语法可以删除索引中指定 doc id 的文档。执行以下命令,删除 doc id 为 1 的文档。
DELETE books/_doc/1
除了单条更新文档以外,我们还可以使用 Delete By Query API 来根据查询条件批量删除文档。执行以下命令,删除所有 pageCount 小于等于 400 的文档。
POST books/_delete_by_query
{
"query": {
"range": {
"pageCount": {
"lte": 400
}
}
}
}
9 索引设置
本小节将指导您如何设置 Elasticsearch 中的索引。
Elasticsearch 便捷的特性使得我们可以在不对索引做任何设置的情况下,便可以对索引进行读写操作。然而,默认设置有时候并不能满足我们的需求。
比如说,我们有一个 3 节点 Elasticsearch 集群,我们想在搜索数据时尽可能地利用多节点的优势,提高搜索的效率。那么我们可以在 settings 中通过 number_of_shards 参数修改索引的分片数。
再比如,默认情况下,数字类型的字段将被映射为 long 类型,pageCount 字段表示书籍的页数,数字并不会很大。那么我们可以在 mappings 中显式指定 pageCount 字段的类型为 integer,从而节省存储空间。
执行以下命令,创建一个新的索引 index-1,设置索引分片数为 3,设置 pageCount 字段的类型为 integer。
PUT index-1
{
"settings": { // 索引设置
"number_of_shards": 3 // 设置索引分片数,默认是 1
},
"mappings": { // 字段映射
"properties": {
"pageCount": {
"type": "integer" // 将字段类型设置为 integer,节省存储空间
}
}
}
}
查看索引设置。
GET index-1
返回结果如下。
{
"index-1" : {
"aliases" : { },
"mappings" : {
"properties" : {
"pageCount" : {
"type" : "integer" // 字段类型为 integer
}
}
},
"settings" : {
"index" : {
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_content"
}
}
},
"number_of_shards" : "3", // 索引分片数
"provided_name" : "index-1",
"creation_date" : "1655965811025",
"number_of_replicas" : "1",
"uuid" : "pP-M1Re2Qg2k2H6vztvkYg",
"version" : {
"created" : "8020399"
}
}
}
}
}
10 文本分析
本小节将指导您如何使用 Analyze API 测试分析器,以及如何自定义分析器。
在第 5 小节中,我们提到了 standard 和 keyword 两个分析器,这两个分析器属于 Elasticsearch 内置的分析器,我们可以直接拿来使用。有关 Elasticsearch 内置分析器的详情参见 Built-in analyzer reference。
Elasticsearch 提供了 Analyze API 用于查看分词器是如何解析文本内容的,在为字段设置分析器之前可以使用 Analyze API 来测试分析器是否满足需求。
执行以下命令,使用默认的 standard 分析器分析文本。
POST _analyze
{
"analyzer": "standard", // standard 是默认使用的分析器,可以省略
"text": "Elasticsearch in Action."
}
返回结果如下,文本被切分为 elasticsearch, in, action 3 个单词,去掉了末尾的句号,并且转换为小写,tokens 数组中的每个参数含义如下:
- token: 切分后的词项。
- start_offset: 词项在文本中的起始偏移。
- end_offset: 词项在文本中的结束偏移。
- type: 词项的类型。
- position: 分词的位置,第 1 个词项从 0 开始。
{
"tokens" : [
{
"token" : "elasticsearch",
"start_offset" : 0,
"end_offset" : 13,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "in",
"start_offset" : 14,
"end_offset" : 16,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "action",
"start_offset" : 17,
"end_offset" : 23,
"type" : "<ALPHANUM>",
"position" : 2
}
]
}
使用 whitespace 分析器分析相同的文本。
POST _analyze
{
"analyzer": "whitespace",
"text": "Elasticsearch in Action."
}
返回结果如下。可以发现 whitespace 分析器根据空格切分单词,不做小写转换,也不会去除标点符号。
{
"tokens" : [
{
"token" : "Elasticsearch",
"start_offset" : 0,
"end_offset" : 13,
"type" : "word",
"position" : 0
},
{
"token" : "in",
"start_offset" : 14,
"end_offset" : 16,
"type" : "word",
"position" : 1
},
{
"token" : "Action.",
"start_offset" : 17,
"end_offset" : 24,
"type" : "word",
"position" : 2
}
]
}
使用 keyword 分析器分析文本。
POST _analyze
{
"analyzer": "keyword",
"text": "Elasticsearch in Action."
}
返回结果如下,keyword 分析器不会对文本进行分词处理,原始文本被完整地保留为一个词项。
{
"tokens" : [
{
"token" : "Elasticsearch in Action.",
"start_offset" : 0,
"end_offset" : 24,
"type" : "word",
"position" : 0
}
]
}
如果我们想要对索引中已有字段的分析器进行测试,可以通过以下方式指定索引字段的分析器对文本进行分析。category.keyword 是 keyword 类型的字段,因此测试文本的时候使用的便是 keyword 分析器。
POST books/_analyze
{
"field": "category.keyword",
"text": "Cloud Compute"
}
返回结果如下。
{
"tokens" : [
{
"token" : "Cloud Compute",
"start_offset" : 0,
"end_offset" : 13,
"type" : "word",
"position" : 0
}
]
}
以上提到的 standard, whitespace, keyword 三种分析器都是 Elasticsearch 内置的分析器,我们也可以根据实际需求自定义分析器。
一个标准的 Analyzer(分析器)由以下 3 部分组成:
- Character filters(字符过滤器):对输入的文本字符进行第一步处理,例如去掉 HTML 标签(htlm_strip),或者将表情字符转换成英文单词(mapping)等。
- Tokenizer(分词器):按照指定的规则对文本进行分词处理,例如按照空格切分单词(whitespace)。分词器还负责标记每个单词的顺序、位置以及单词在原文本中开始和结束的偏移量。
- Token filters(分词过滤器):对切分后的单词进行处理,进而对分词结果进行归一化处理,例如字母的大小写转换(uppercase/lowercase),删除停用词(stop),标记同义词(synonym),提取词干(snowball)等等。

在分析器中,Tokenizer 是必须设置的,有且只有一个,Character filters 和 Token filters 是可选的,以数组的形式进行设置,按顺序执行。
如下所示,创建一个自定义分析器 my-analyzer,Character filters 使用 html_strip 字符过滤器剔除输入文本中 HTML 标签,tokenizer 使用 whitespace 分词器按照空格切分单词,Token filters 使用 uppercase 字符过滤器将切分后的每个单词转换为大写。最后在 mapping 中设置 content 字段使用我们自定义的分析器 my-analyzer。
PUT my-index
{
"settings": {
"analysis": {
"analyzer": {
"my-analyzer": {
"type": "custom", // 自定义分析器
"char_filter": [ // 字符串过滤器
"html_strip" // 去掉 HTML 标签
],
"tokenizer": "whitespace", // 分词器,按照空格切分单词
"filter": [ // 分词过滤器
"uppercase" // 将切分后的每个单词转换为大写
]
}
}
}
},
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "my-analyzer" // 设置字段使用自定义分析器
}
}
}
}
测试自定义分析器。
POST my-index/_analyze
{
"field": "content",
"text": "<h1>Quick fox jumps</h1>"
}
返回结果如下所示,输入的字符串 "<h1>Quick fox jumps" 分别经过了 Character filters(去掉 HTML 标签),Tokenizer(根据空格切分),Token filters(大写字母转换),最后将结果 ["QUICK", "FOX", "JUMPS"] 写入倒排索引中。
{
"tokens" : [
{
"token" : "QUICK",
"start_offset" : 4,
"end_offset" : 9,
"type" : "word",
"position" : 0
},
{
"token" : "FOX",
"start_offset" : 10,
"end_offset" : 13,
"type" : "word",
"position" : 1
},
{
"token" : "JUMPS",
"start_offset" : 14,
"end_offset" : 19,
"type" : "word",
"position" : 2
}
]
}